Jonas is CTO of TypeSafe a company that provides a Reactive Platform which helps to deliver responsive, resilient and event-driven applications. Typesafe spearheaded the Reactive Manifesto which defines a common vocabulary for reactive applications.
Unsurprisingly, Jonas presentation was about why and how to build a reactive application!
We’re entering a new era. When building an application we now often have to deal with mobile devices, cloud computing, distributed components. We need to build softwares that are real-time, responsive…

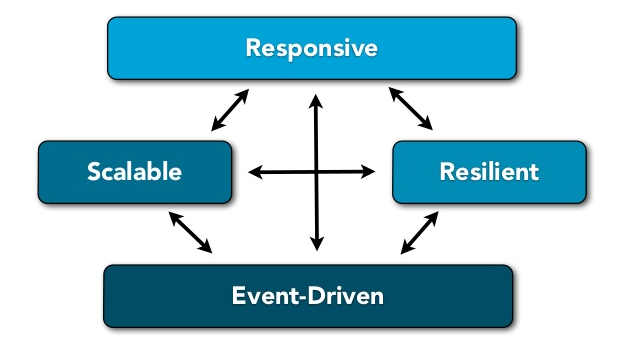
As Jonas said, our applications now have to react to:
- events -> being event-driven
- load -> being scalable
- failure -> being resilient
- users -> being responsive
In one word, they need to be reactive!
First of all, we need to go async! (see Amdahl’s law). We do need to avoid blocking processes (which kills scalability). An event-driven system makes use of asynchronous message passing which gives lower latency, better throughput and bring more loosely coupled components.
Our applications need to be scalable, meaning being able to be expanded on demand. Better scalability comes with systems that are built of isolated components that share nothing with loose coupling and that communicate asynchronously. We need to minimize contention and maximize locality of reference. One thing that need to be kept in mind while dealing with distributed computing is the 8 fallacies of Peter Deutsch: the network is inherently unreliable!
We also need to build resilient systems that are capable of recovering quickly in case of problems. We need to avoid defensive programming where errors are mixed with business logic and disseminated everywhere in the code. Our clients should only deal with validation errors, not with applications’ ones. Our services should be built both with a dedicated supervisor which role would be to handle things in case of issues. It should be up to the supervisor to decide what to do (kill, suspend, resume, …) and so business logic and error handling are decoupled!
Last but not least: responsiveness! We need to keep the latency consistent. We need to make asynchronous and non blocking requests and responses and switch from pull to push so that our UI’s are interactive and always synchronized!

Links: